LLM Prompting: an energy consumption study
Fedor Baryshnikov, Jari de Keijzer, Tobias Veselka, Stilyan Penchev.
Group 27.
This study will focus on analysing the energy consumption of two LLM-related tasks. Firstly, we will analyse how the length of a question input prompt affects the energy consumption of an LLM generating a response. Secondly, we will study three different models by three different developers and compare their energy efficiency when generating a response to a question.
LLM Prompting: an energy consumption study
Introduction
In November 2022, OpenAI released ChatGPT (Matt Casey, 2023) - arguably the first Large Language Model (LLM) available to the general public. This, alongside the recent Artificial Intelligence (AI) revolution, marked a real turn in what we perceive computers to be capable of - no longer could programs only deal with scenarios pre-defined by a programmer; they now also (appeared to) reason for themselves.
However, with subsequent research into the LLM-production pipeline, LLM developers have received a vast amount of criticism for the negative social and environmental impact that LLMs and their production cause. Arguably the most common criticism of LLM developers is the unethical and oftentimes illegal sourcing of training data for their models. These claims often touch base on the infringement of copyright or GDPR to prove the wrong-doings of LLM developers. However, another aspect that must be considered is the environmental impact of LLMs - specifically, the energy consumed to both test and train these LLMs. Jacob Morrison et al. found that training a 13 billion parameter model from the OLMo model family consumed an estimated 230 MWh of electricity - which they state is enough to power the average US home for 21 years.
This study will focus on analysing the energy consumption of prompting LLMs. Specifically, it is our goal to address two specific questions - first, we will study how the length of an input prompt affects the energy consumption of an LLM producing a response. Second, we will compare three different 8 billion parameter models, rnj-1, Llama 3.1 and Deepseek-r1 (developed by Essential AI, Meta and Deepseek respectively) in terms of their energy consumption to study how much variation in energy efficiency there is between different LLM developers.
Methodology
Before running the tests, the computer must be warmed up. This is done because higher temperature results in higher energy consumption due to the higher electrical resistance of electrical conductors - thus, for a fair test, we must make sure the computer is sufficiently warmed up for our tests to take place under the same thermal conditions. To accomplish this, we ran a CPU-intensive task (in our case, calculating Fibonacci numbers) for 5 minutes before the start of our tests. Furthermore, a 5-second sleep period is used between measurements, to prevent collateral tasks from the previous measurement from affecting the next measurement. The 5-second duration is a tradeoff between minimizing tail energy consumption of previous measurements and allowing the measurements to be run within a reasonable timeframe.
To further improve the validity of our tests, we must minimise the effect of external factors on our test results. Thus, the following measures have been to reduce confounding variables:
- Adaptive screen brightness disabled
- Monitor set to 50% brightness
- Display sleep disabled
- All applications aside from VS Code and Ollama (used to run our LLMs) closed
- Background services limited as much as possible (constrained by services required by OS)
- Wi-Fi and Bluetooth disabled
- AirDrop disabled (not applicable as we are not using MacOS, but a recommendation if this study is replicated)
- Power Plan set to balanced
- Notifications disabled
- No mouse and keyboard plugged in
- The tests are performed in a room where no human is present to keep the temperature stable as much as possible
Additionally, all of our tests will be run on the same computer with the following hardware:
- CPU: Intel Core i7-13650HX
- GPU: NVIDIA GeForce RTX 4050
- RAM: 24 GB DDR5-4800
- Operating System: Linux Ubuntu 24.04
The prompts tested were taken from dataset-factoid-webquestions (Petr Baudis et al.), a dataset licensed under the CC-BY 4.0 License. This dataset was modified to only include each prompt alongside the count of words for said prompt. To perform energy consumption measurements, we will use EnergiBridge, an energy measurement utility, which will record the energy and power used by the CPU and GPU respectively for each prompt, which will then be converted to total energy usage in Joules. All of the evaluated LLMs will be run locally via Ollama.
Part 1: The significance of a prompt’s length on an LLM’s energy efficiency
Our first test will consist of evaluating how much of an effect the length of a prompt has on the energy consumed by an LLM while generating an answer. It is our assumption that a longer prompt will result in an LLM consuming a greater amount of energy, however we are not sure exactly what kind of relation there will be.
For this part, we chose to use Deepseek’s deepseek-r1 7 billion parameter model. This is the only model we will be using for this test to limit the effect of model infrastructure, parameter size and any other confounding variables that could affect this test.
The data for our test will consist of 36 total prompts: six prompts of 5 through 10 words inclusive. Each prompt will be evaluated 30 times to reduce variance and obtain a statistically reliable estimate of energy usage for each prompt length.
Part 2: How efficient are different developers at producing energy-efficient LLMs?
For this test, we wanted to see how efficient different LLM models made by different companies were. To select our LLMs, we looked for 8B parameter LLMs that were released within at most 1.5 years of each other. We chose three different ‘types’ of LLM developers - a relatively small LLM developer, Essential AI, a medium-sized developer, Deepseek, and a large developer, Meta AI; we thus chose the 8 billion rnj-1, deepseek-r1 and llama3.1 models respectively.
To perform this test, we will sample twenty prompts of varying length at random from our dataset (note: we use random_state=0 for reproducibility). For each prompt, 30 executions will be repeated on each of the three chosen LLMs.
Results
After setting up the code to run the experiment automatically, and making sure the computer was warmed up and all confounding variables were limited, we ran the experiment. For each of the independent variables, we calculated:
- Max: the most energy consumed by a single LLM run, in Joules
- Min: the least energy consumed by a single LLM run, in Joules
- Mean: the average amount of energy consumed across all the runs of with this independent variable value, in Joules
- Standard Deviation: the standard deviation across all the runs with this independent variable value, in Joules
Note: e.c. stands for “energy consumed”
Part 1
Running part one of our experiment took a total of 36 prompts (6 prompts for the 6 prompt lengths), each executed 30 times, resulting in 1080 total response generations.
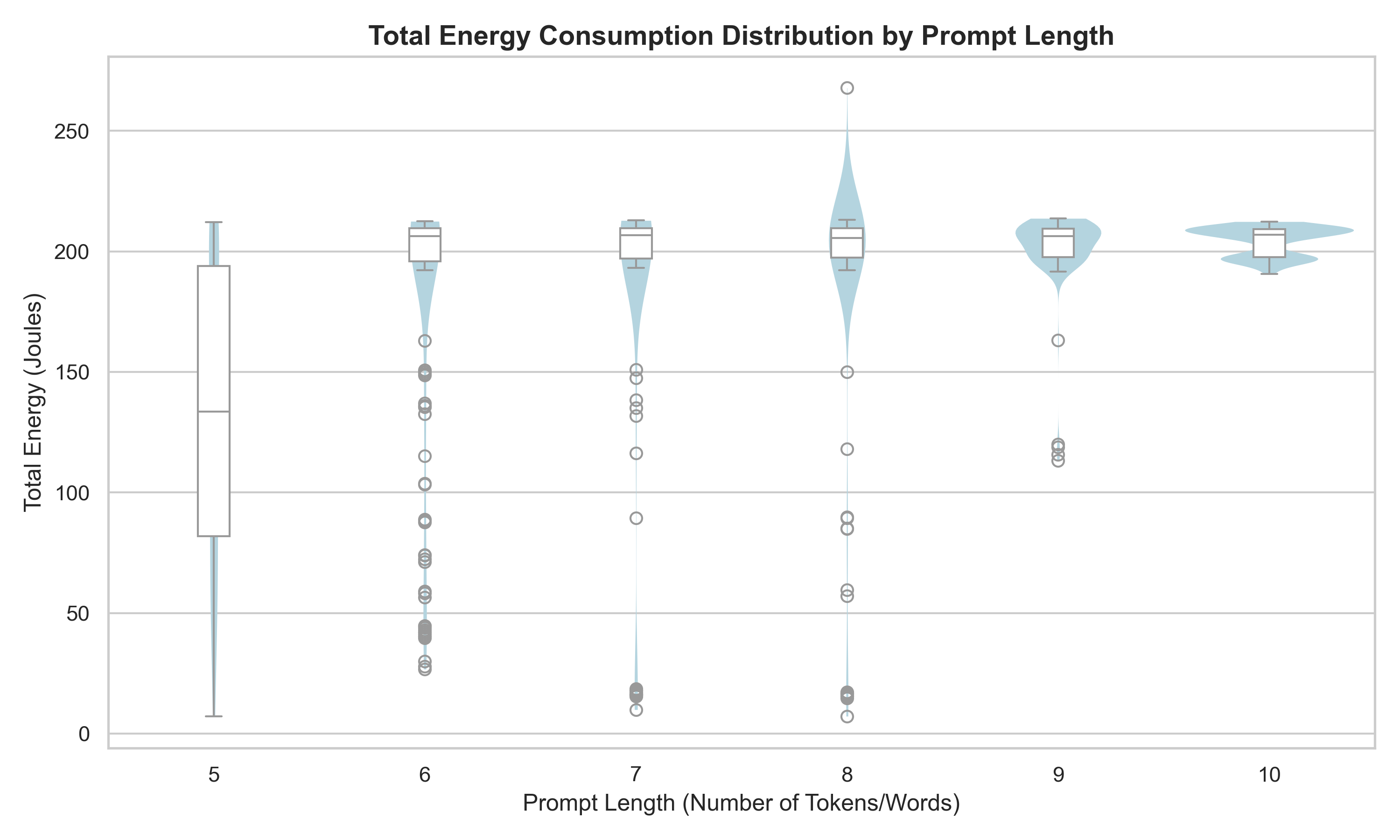
In the plot below, we can see the average energy consumption of the LLM for each prompt length. The main difference we can see is that the spread of the energy consumption for the 5-word prompts is much bigger than the 10-word prompts.
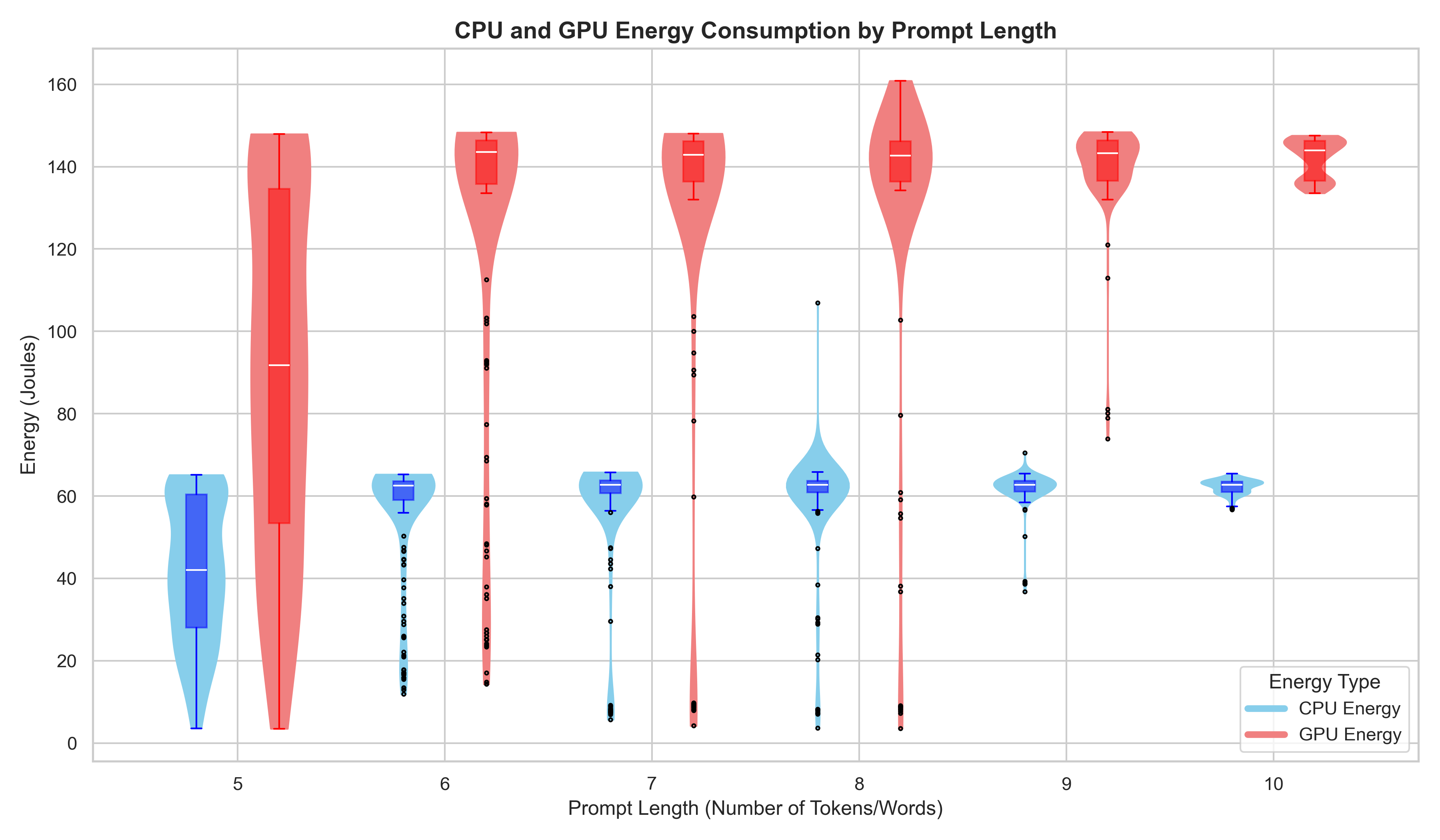
In the plot below, we can see the average energy consumption of the CPU and GPU for each prompt length. As expected the GPU uses more energy than the CPU, and again here the spread is higher on the shorter length prompts.
This next table shows the max, min, mean and standard deviation of the energy consumed for each prompt length. We can see that the max values are almost all very similar, except for an outlier in the 8 word prompts. We can also see that the means of the different length prompts are very similar except for the 5-word prompt. As explained before the spread is more in the shorter length prompts, which is reflected in the standard deviation values being higher for the shorter length prompts. The minimum values get higher with the length of the prompts with an outlier for the 6-word prompt.
Total energy consumption statistics:
| Prompt length | Max e.c. (J) | Min e.c. (J) | Mean e.c. (J) | Standard Dev e.c. (J) |
|---|---|---|---|---|
| 5 | 212.15 | 7.09 | 131.04 | 60.94 |
| 6 | 212.45 | 26.69 | 181.23 | 53.10 |
| 7 | 212.79 | 9.89 | 186.22 | 53.82 |
| 8 | 267.79 | 7.16 | 190.44 | 47.57 |
| 9 | 213.66 | 113.20 | 202.26 | 14.52 |
| 10 | 212.32 | 190.68 | 204.31 | 5.94 |
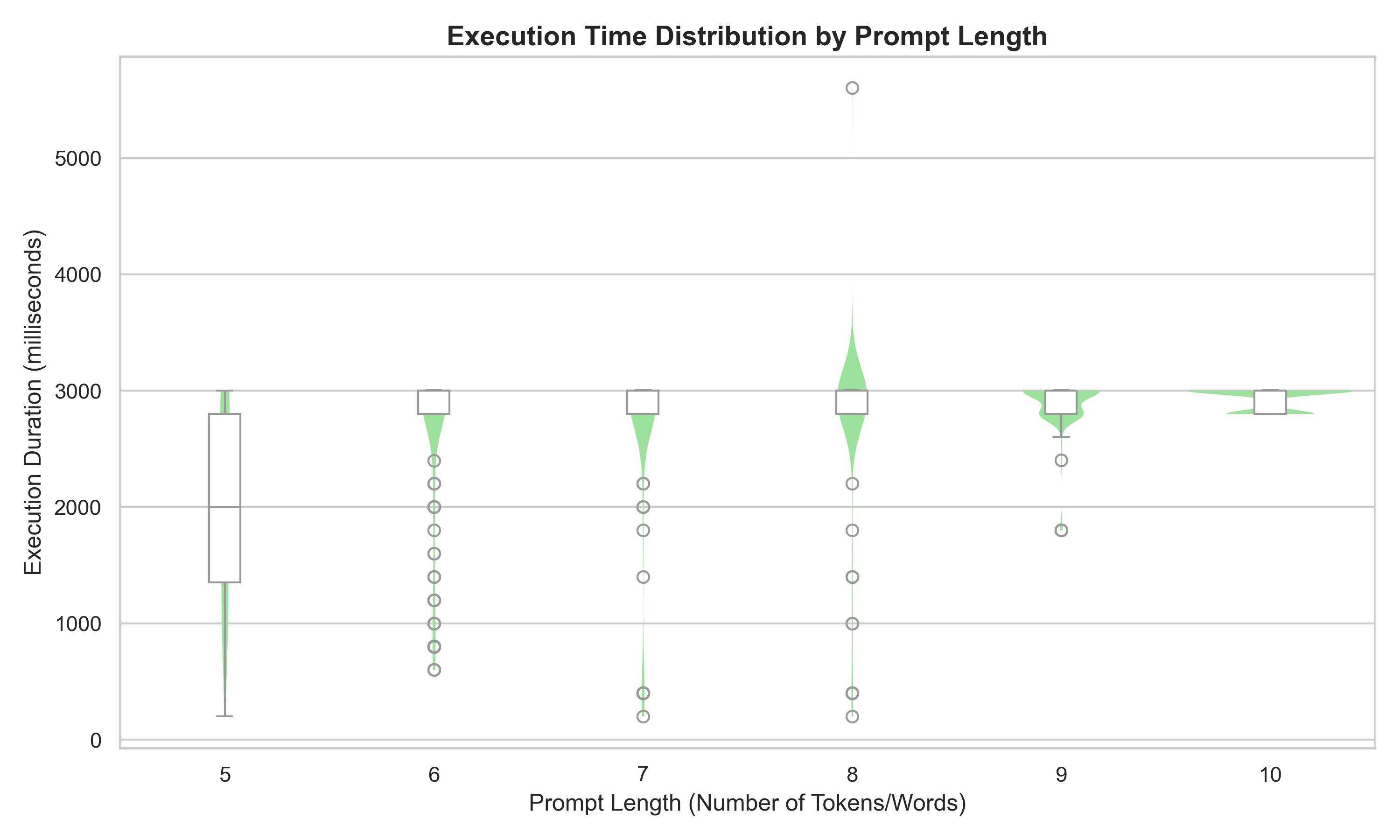
In this next plot we can see the execution duration and the prompt length is very similar compared to the energy consumption plot, which is expected as energy is power multiplied by time, and power is relatively stable across different executions of the same prompt.
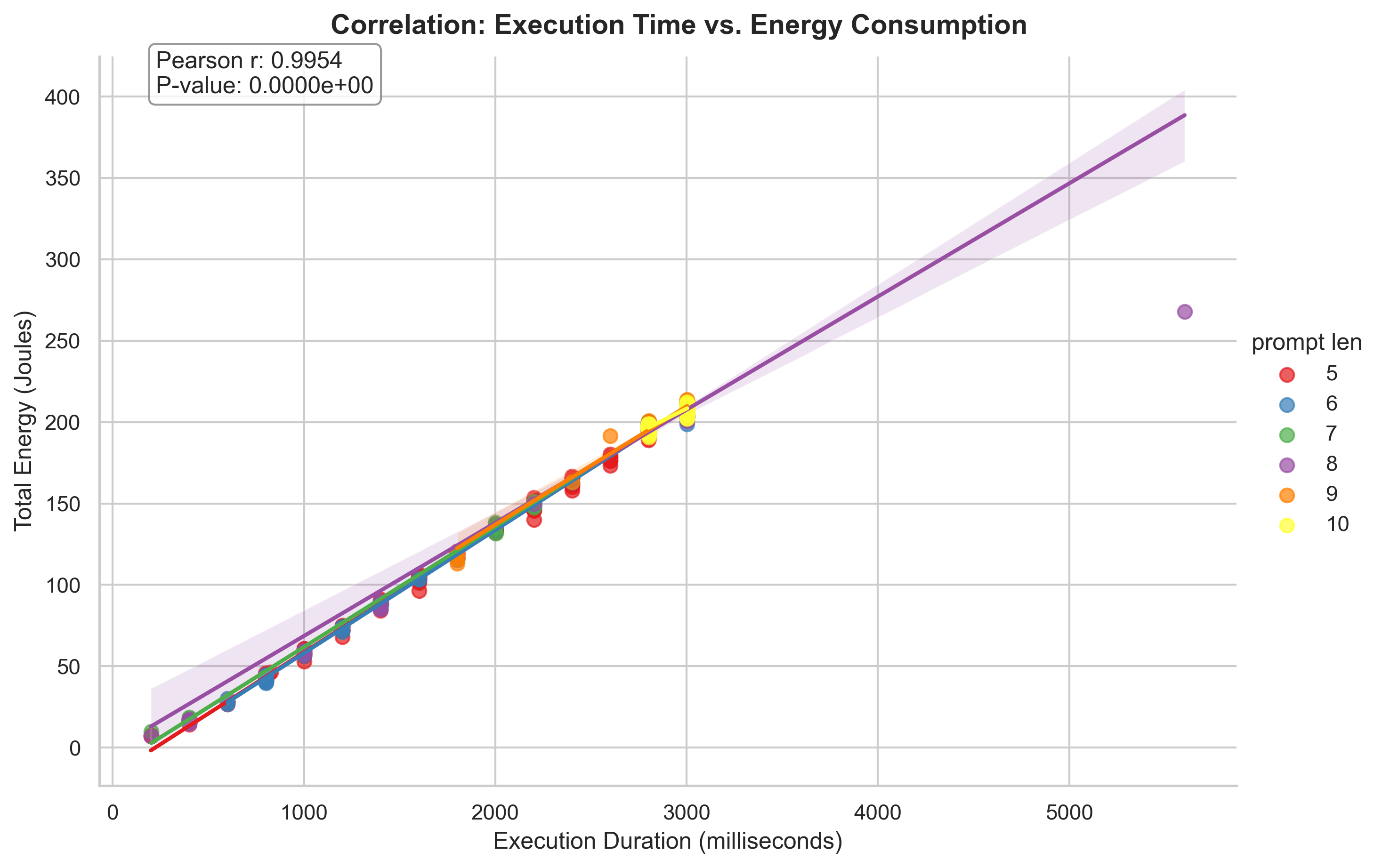
This last plot for part 1 shows the correlation between the time taken to generate a response and the energy consumed, also split up into prompt length. We can see that there is an almost perfect linear correlation between the time taken to generate a response and the energy consumed, which is expected as energy is power multiplied by time, however we also see that the correlation is the same over all prompt lengths. This indicates that the variance in energy consumption is mostly due to the variance in time taken to generate a response, and that the prompt length does not have a significant effect on the energy consumption.
Part 2
In the comparison of three models with identical parameter counts, The deepseek-r1 and llama3.1 models show similar inter quartile ranges (IQR) regarding the energy consumption. However, Deepseek’s proved itself to be less energy-efficient on average. While Meta’s distribution -ignoring outliers- has a tail outside the IQR tending towards lower energy usage, DeepSeek’s distribution is characterized by a tail of higher energy consumption values, indicating more frequent cases of increased energy usage.
Essential AI’s rnj-1 model exhibits a significantly wider spread in energy consumption compared to the other models. This model gravitates to a more uniform distribution across the prompts, as evidenced by the larger IQR.
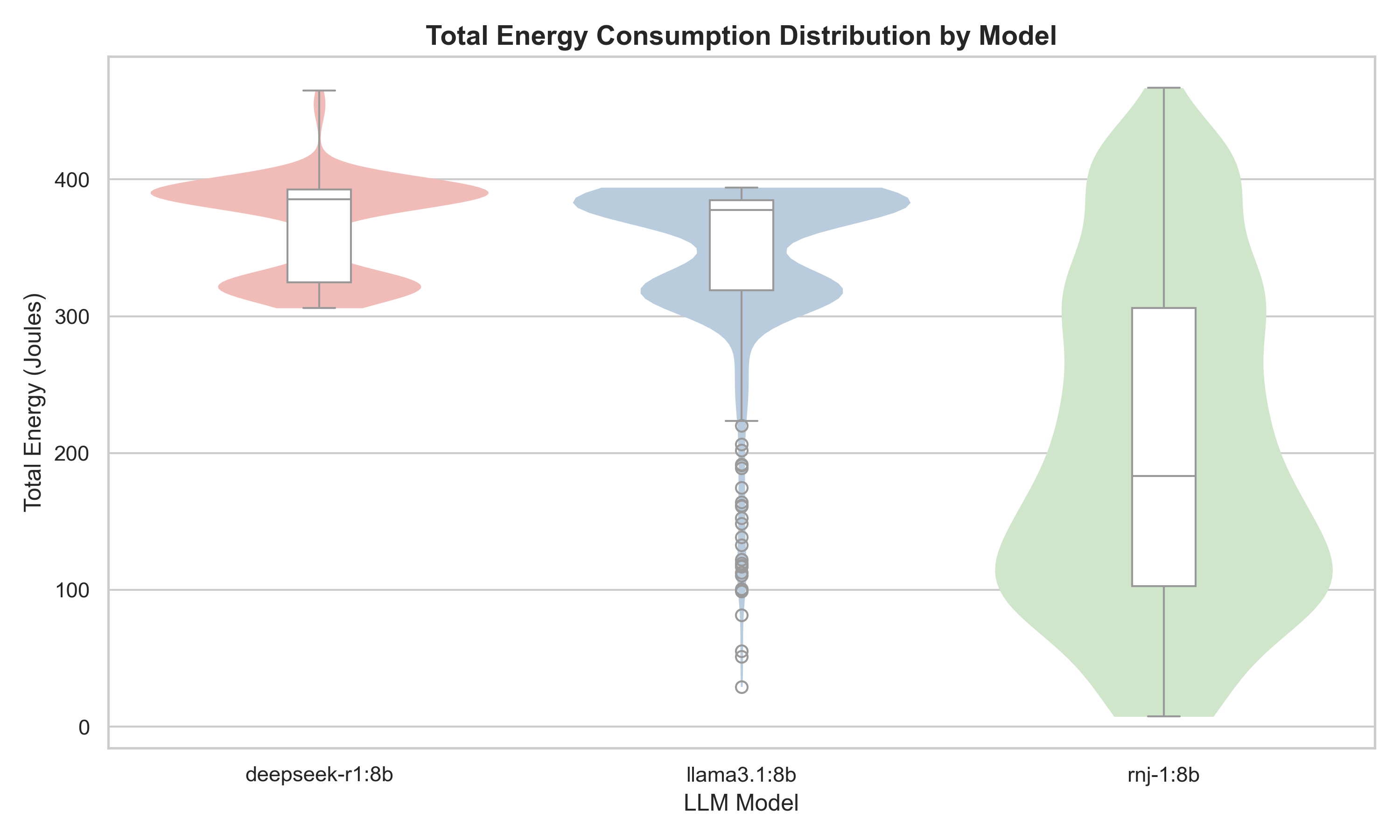
The aforementioned difference in IQR distance and spread, as well as other statistical metrics have been tabulated below.
| Model | Max e.c. (J) | Min e.c. (J) | Mean e.c. (J) | Standard Dev e.c. (J) |
|---|---|---|---|---|
| deepseek-r1 | 465.06 | 305.99 | 366.33 | 36.06 |
| llama3.1 | 394.15 | 29.16 | 345.37 | 59.20 |
| rnj-1 | 466.90 | 7.405 | 205.44 | 119.34 |
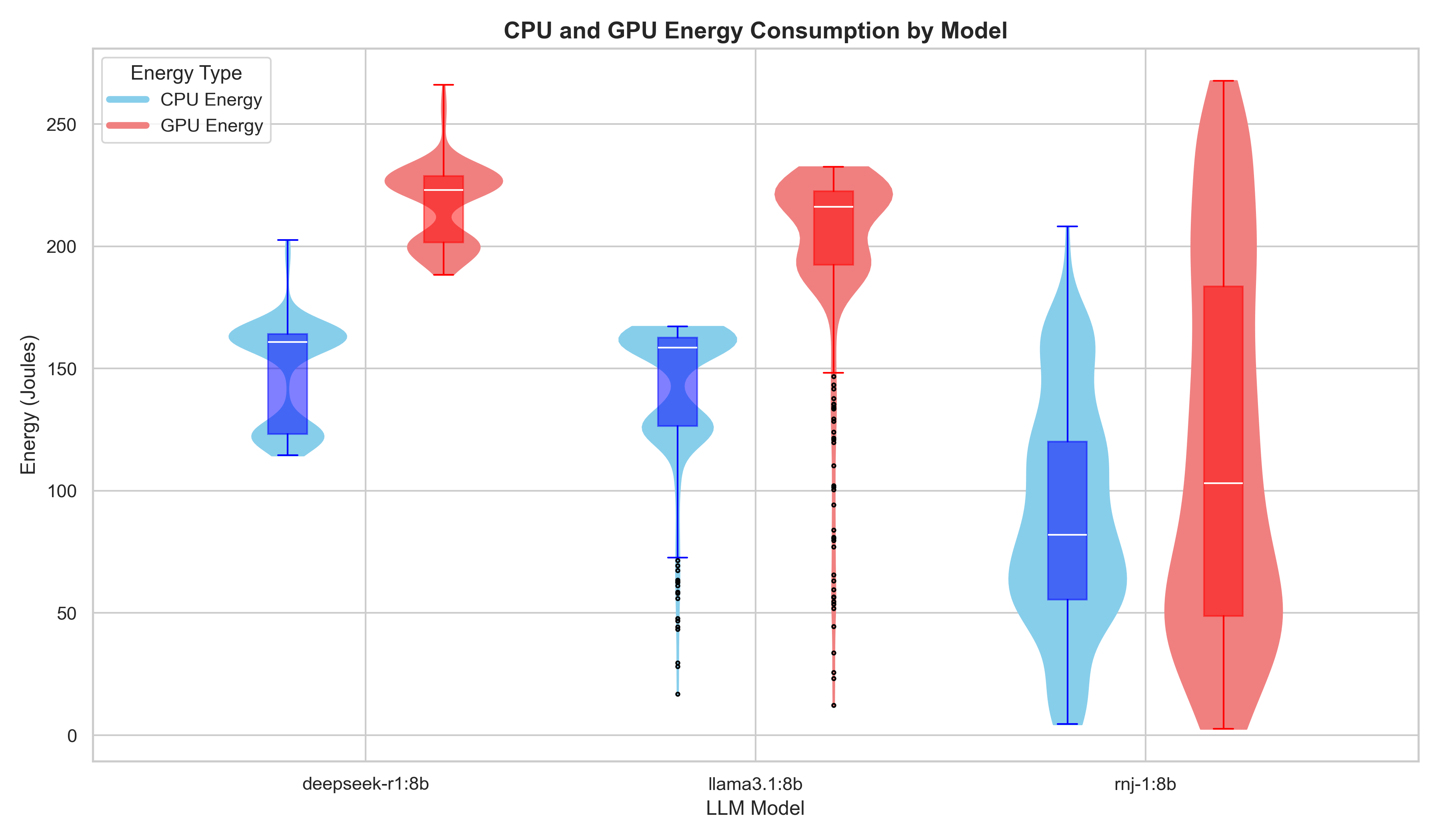
The energy usage of the CPU and the GPU can be seen in the image below. All models show the same trend: the graphics card is the primary driver of energy usage, outpacing the CPU’s average demand.
Analysis
Part 1
What we noticed in the results section for part one is that there is much bigger spread in the energy consumption for the shorter prompts, yet the means were quite similar (except for the 5-word prompts, which had a bit lower mean energy consumption). Thus, we can conclude that the length of a prompt does not have a significant effect on the energy consumption of an LLM when generating a response, but that shorter prompts have more variance in their energy consumption than longer prompts. This could be because the LLM has more ‘freedom’ to generate a response for a shorter prompt, while for a longer prompt, the LLM is more constrained in its response generation - thus, the energy consumption is more consistent across different executions of the same prompt. Another potential reason the prompt length has little effect on the energy used could be an indication of what part of the LLM response generation chain actually uses the power - in this case, our results would indicate that it is the response generation element of the LLM, rather than the LLM interpreting the prompt, which takes up the majority of the energy. However this is just speculation and further research is needed to confirm this.
What we also noticed is that there is an almost perfect linear correlation between the time taken to generate a response and the energy consumed, which is expected as energy is power multiplied by time, and power is relatively stable across different executions of the same prompt. So we can conclude that the variance in energy consumption is mostly due to the variance in time taken to generate a response.
Overall, we can’t say that the length of a prompt has a significant effect on the energy consumption of an LLM when generating a response, but that shorter prompts have more variance in their energy consumption than longer prompts and that the execution time is the most important in factor in determining the energy consumption of an LLM when generating a response. What influences this, we cannot conclude from this experiment and further research is needed to determine the factors that influence the execution time.
Part 2
The main pattern is that model choice has a clear effect on both execution time and energy use. Across the same prompt set and repetitions, rnj-1:8b is generally the fastest and lowest-energy model, llama3.1:8b is in the middle, and deepseek-r1:8b tends to be the slowest and most energy-intensive. We also see that rnj-1:8b has a wider spread in some plots, which suggests less consistent run-to-run behavior than the other two models. We must, however, note that a lower energy consumption or faster runtime is not necessarily an indication of better performance, as the quality of the produced result is not evaluated. One measurement with negative total energy was removed in the plotting step, indicating a likely sensor/measurement artifact rather than real negative consumption.
From the CPU/GPU split, GPU energy is consistently higher than CPU energy for all models, which is expected for LLM inference workloads. This suggests that model-level efficiency differences mainly show up through how much GPU compute time each model needs to produce a response. In conclusion, unlike P1 (where prompt length had limited effect on average energy), P2 shows that model implementation/behavior is a major factor in sustainability outcomes. However, explaining why one model is faster or more stable than another requires further profiling (token counts, decoding behavior and hardware-level utilization).
Overall, we can see that the two larger companies’ models (Meta’s Llama 3.1 and Deepseek’s deepseek-r1) perform fairly similarly in terms of energy consumption - this may indicate a “sweet spot” for energy consumption for a model. It is interesting to note that Essential AI’s rnj-1 model does, on average, consume less energy; however, this has to be taken with respect to the quality of the model output, which is not in the scope of this study.
Limitations
Despite our best attempts to make the study as robust as possible, there are certain parts of our research that were limited and could be improved upon. The first limitation we faced is the fact that EnergiBridge captures the total energy consumption of a system - despite our attempts to limit confounding variables (see methodology), certain background operating system processes could not be stopped or the impact of them be measured. Additionally, the tests were only performed on one operating system, Ubuntu Linux - the reliability of our results could be further improved by repeating the tests on different operating systems such as MacOS or Windows and averaging out the result from all the operating systems.
Another limitation is the use of a mere 6 prompts of each length for our first test. The reason for this is because we test six total prompts, of lengths five to ten inclusive, 30 times each. This results in a total of 1080 total response generations, whereas for the second analysis, a total of 1800 responses were generated, totalling roughly 8 hours of measuring time.
Another limitation was the release date of the different LLM compared in part two. We primarily selected our LLMs based on the parameter size, while looking for LLMs that were released roughly within 1.5 years of one another. With LLMs becoming publicly available within the last decade, 1.5 years may still be considered a relatively long time - thus, our experiment could be improved by using newer LLMs released within a shorter timeframe of one another.
Another limitation was that we did not evaluate the quality of our LLM generated responses. A good analysis would have been a ratio of quality to energy consumed per LLM, which would have given us a good picture of how truly effectively an LLM consumes energy when generating a response.
Conclusion
This study focused on two main topics: analysing how the prompt length affects an LLM producing a response, and also how different developers compare when it comes to their models’ energy efficiency. To ensure a fair test, we took careful precautions to eliminate factors such as computer temperature, varying specs and varying settings from affecting our tests. For the first part of our study, we observed that the prompt length plays little importance when it comes to an LLM’s energy consumption, yet longer prompts tend to give more reliable measurements of energy consumption. For part two, we noticed similar energy consumption between our large and medium sized LLM developers, Meta and Deepseek, with Meta’s models occasionally consuming much less energy. Essential AI’s rnj-1 model consistently consumed less energy than Meta and Deepseek’s models, with its upper quartile still being below the other two’s lower quartile. However, this is not necessarily an indication of quality due to our study not attempting to evaluate the quality of the responses.
Code
All of the code used for this study can be found here.
Back to all projects