Comparing the Energy Efficiency of Standard JSON and orjson
Cristian Benghe, Alexandru Mititelu, Antoni Nowakowski, Andrei Paduraru.
Group 23.
This project compares the energy consumption of data serialization in Python, namely how the standard json library compares to the orjson alternative. We investigate whether the performance gains from using a Rust-powered JSON library translate into meaningful energy savings through the "Race to Sleep" principle.
Introduction
Data serialization is a fundamental operation that underpins virtually every modern software application. From web APIs exchanging data between clients and servers, to configuration files, logging systems, and inter-process communication-JSON (JavaScript Object Notation) has become the de facto standard for data interchange1. In Python, the built-in json module is the default choice for millions of developers worldwide, handling everything from simple configuration parsing to processing massive datasets in data engineering pipelines.
However, as software systems scale and sustainability becomes an increasingly critical concern, the energy efficiency of these ubiquitous operations deserves scrutiny. The standard Python json library, while reliable and well-documented, is often criticized for its performance limitations, particularly when handling large volumes of data2. This inefficiency stems from Python’s interpreted nature and the library’s pure-Python implementation of certain components, leading to higher CPU utilization and longer execution times.
Enter orjson-a high-performance JSON library for Python that promises to revolutionize serialization performance. Written in Rust and compiled as a native extension, orjson leverages SIMD (Single Instruction, Multiple Data) instructions to process multiple data elements simultaneously3. Benchmarks suggest that orjson can be up to 10 times faster than the standard library for certain operations, raising an intriguing question for sustainable software engineering: Does this speed advantage translate into meaningful energy savings?
This study investigates the potential for energy optimization by examining the “Race to Sleep” hypothesis. This principle suggests that faster execution allows the CPU to complete its work more quickly and return to a low-power idle state sooner, thereby reducing the total energy consumed by the system4. If orjson’s performance improvements follow this pattern, it could offer a compelling case for adopting alternative libraries not just for speed, but for sustainability.
Motivation
The motivation for this study is threefold, addressing both practical software engineering concerns and broader sustainability implications.
The Scale of JSON Operations
JSON serialization and deserialization are among the most frequently executed operations in modern software systems. Consider a typical web service: every API request involves parsing incoming JSON data, processing it, and serializing the response. A moderately trafficked service might handle millions of such operations daily. In data processing pipelines, ETL (Extract, Transform, Load) jobs routinely serialize and deserialize gigabytes of data. While each individual operation consumes a negligible amount of energy, the cumulative impact at scale is substantial.
Research indicates that the ICT sector could account for up to 14% of global carbon emissions by 20405. Within this sector, data centers and cloud computing represent a significant portion of energy consumption. Optimizing fundamental operations like JSON parsing could yield measurable reductions in energy usage across the industry.
The Promise of Native Extensions
The emergence of high-performance Python libraries written in systems languages like Rust and C++ represents a significant trend in the Python ecosystem. Libraries such as orjson, pydantic-core, and polars demonstrate that Python’s flexibility can be combined with near-native performance. However, the energy implications of these alternatives remain largely unexplored.
The “Race to Sleep” hypothesis provides a theoretical framework for understanding how faster execution might reduce energy consumption. When a CPU completes a task more quickly, it can transition to a lower power state (such as C-states in Intel processors) sooner. The key question is whether the energy saved during idle time exceeds any additional energy consumed due to higher instantaneous power draw during the faster execution.
Practical Developer Impact
For software developers and organizations, understanding the energy implications of library choices can inform more sustainable development practices. If simply swapping import json for import orjson can reduce energy consumption by a meaningful margin, this represents a low-effort, high-impact optimization. Such findings could influence library selection guidelines, code review practices, and organizational sustainability initiatives.
Background
JSON Serialization in Python
JSON (JavaScript Object Notation) is a lightweight data interchange format that is easy for humans to read and write, and easy for machines to parse and generate1. In Python, the standard json module provides functions for encoding Python objects into JSON strings (json.dumps()) and decoding JSON strings into Python objects (json.loads()).
The standard library implementation prioritizes correctness, compatibility, and simplicity over raw performance. It handles edge cases gracefully, supports custom encoders and decoders, and works reliably across all Python versions. However, these benefits come at a cost: the implementation involves significant overhead from Python’s dynamic typing, function call overhead, and lack of low-level optimizations.
The orjson Library
orjson is a fast, correct JSON library for Python 3.8+3. It differs from the standard library in several key ways:
-
Native Implementation: Written in Rust and compiled as a native Python extension, orjson bypasses Python’s interpreter overhead for the core serialization logic.
-
SIMD Optimization: orjson utilizes SIMD instructions to process multiple characters or values simultaneously. This is particularly effective for parsing strings and numerical data.
-
Memory Efficiency: The library employs optimized memory allocation strategies, reducing the overhead associated with Python’s memory management.
-
Strict Compliance: Despite its speed optimizations, orjson maintains strict JSON compliance and handles Unicode, floating-point numbers, and edge cases correctly.
Benchmarks on the orjson GitHub repository show speedups ranging from 2x to 10x compared to the standard library, depending on the data structure and operation3.
The Race to Sleep Principle
The “Race to Sleep” principle is a concept in energy-efficient computing that suggests completing computational tasks as quickly as possible to allow the processor to enter low-power states sooner4. Modern processors support multiple power states (P-states for performance and C-states for idle), and the deepest idle states consume significantly less power than active states.
The energy consumption of a task can be modeled as:
\[E = P_{active} \times t_{active} + P_{idle} \times t_{idle}\]Where:
- $E$ is total energy consumed
- $P_{active}$ is power consumption during active processing
- $t_{active}$ is time spent in active processing
- $P_{idle}$ is power consumption during idle state
- $t_{idle}$ is time spent in idle state
A faster library might have a slightly higher $P_{active}$ due to more intensive CPU utilization, but if it significantly reduces $t_{active}$, the overall energy consumption can decrease—provided the system can effectively transition to and remain in low-power states.
Energy Measurement in Software
Measuring software energy consumption accurately requires careful experimental design. Modern Intel and AMD processors provide Running Average Power Limit (RAPL) interfaces that expose energy counters for various power domains, including the CPU package (PKG), CPU cores (PP0), and DRAM6. These hardware counters offer high precision and low overhead, making them suitable for software energy measurements.
Tools like EnergiBridge provide a cross-platform interface to these energy measurements, enabling researchers to correlate energy consumption with specific software operations7.
Research Questions
To guide our investigation and define the scope of our analysis, we have formulated the following research questions:
RQ1. How does the total energy consumption (in Joules) of the orjson library compare to the standard Python json library when performing large-scale serialization and deserialization tasks?
This question addresses the primary objective of our study: determining whether orjson offers measurable energy savings over the standard library. By measuring total energy consumption in Joules, we obtain a direct, hardware-level metric that captures the full energy cost of each operation.
RQ2. How do the energy-saving benefits of orjson scale as the volume of the dataset increases (e.g., comparing 1 GB vs. 5 GB files)?
This question explores whether the relationship between library choice and energy consumption is consistent across different workload sizes. Understanding scaling behavior is crucial for extrapolating our findings to real-world applications, where dataset sizes vary significantly.
Methodology
Experimental Setup
The experiment will be conducted on a Windows 11 machine to ensure a controlled and reproducible environment. To access the CPU’s energy registers (RAPL), we will utilize EnergiBridge in conjunction with an elevated (Administrator) terminal. Windows 11 often restricts access to Model Specific Registers (MSRs) for security reasons; therefore, we will ensure the necessary hardware drivers are active to allow the profiler to log the PP0 Energy Consumption (CPU energy) at a sampling rate of 200ms.
Hardware Configuration
The specific hardware configuration will be documented in the final report to ensure reproducibility. Key specifications include:
- CPU model and frequency
- RAM capacity and speed
- Storage type (SSD/NVMe)
- Operating system version and patch level
Software Configuration
- Python Version: 3.11+ (to ensure compatibility with orjson optimizations)
- orjson Version: Latest stable release
- EnergiBridge Version: 0.0.7 or later
- Operating System: Windows 11
Environmental Controls
To minimize external interference with our measurements, we will implement the following controls:
- Zen Mode Configuration:
- Close all unnecessary applications
- Disable notifications and automatic updates
- Disconnect non-essential peripherals
- Disable network connections during experiments
- Set display brightness to a fixed value
- Maintain consistent room temperature (approximately 25 degrees Celsius)
-
System Warm-up: Before measurements, the system will execute a warm-up routine (Fibonacci computations for 300 seconds) to ensure the CPU reaches a stable thermal state.
- Cooling Period: Between experimental runs, the system will rest for 60 seconds to allow CPU temperature to stabilize and prevent thermal throttling from affecting subsequent measurements.
The Reproducible Scenario
We have developed a Python-based automated scenario that handles both serialization and deserialization. The experimental workflow is as follows:
Data Generation
A pre-generated dummy dataset will be used for consistency. The dataset consists of JSON-serializable Python objects with a mix of:
- Nested dictionaries
- Lists of varying lengths
- String values of different sizes
- Numeric values (integers and floating-point)
- Boolean values and null values
Two dataset sizes will be tested:
- Small dataset: 1 GB (to stress-test single-pass deserialization at a realistic data-engineering scale)
- Large dataset: 5 GB (to evaluate behaviour under sustained, high-memory workloads)
Experimental Procedure
For each library (standard json and orjson), the following steps will be executed:
-
Load Dataset: Load the pre-generated dataset into memory to eliminate disk I/O from measurements.
-
Serialization Phase: Serialize the in-memory Python object into a JSON string 50 times to create a measurable computational load.
-
Deserialization Phase: Deserialize the JSON string back into a Python object 50 times.
-
Energy Measurement: EnergiBridge will measure energy consumption (in Joules) for the combined serialization and deserialization operations.
Statistical Rigor
To ensure statistical significance, we will:
- Perform 30 repeated trials for each configuration (library x dataset size)
- Randomize the order of experiments to minimize systematic bias
- Apply outlier detection using the IQR (Interquartile Range) method
- Verify data normality using the Shapiro-Wilk test
- Use appropriate statistical tests (Welch’s t-test for normal distributions, Mann-Whitney U test otherwise)
- Calculate effect sizes using Cohen’s d and percentage differences
Comparison Framework
We define two experimental versions:
| Version | Library | Description |
|---|---|---|
| Baseline | json |
Standard Python library implementation |
| Improved | orjson |
Rust-based high-performance alternative |
The comparison will evaluate:
- Total energy consumption (Joules)
- Execution time (seconds)
- Power consumption (Watts, derived as Energy/Time)
- Energy per operation (Joules per serialization/deserialization cycle)
Results
This section presents the findings from our experimental comparison of json and orjson across 30 repeated trials. We analyze four key metrics: execution duration, CPU energy consumption, single-core (CORE0) energy consumption, and average CPU power draw.
Duration Analysis
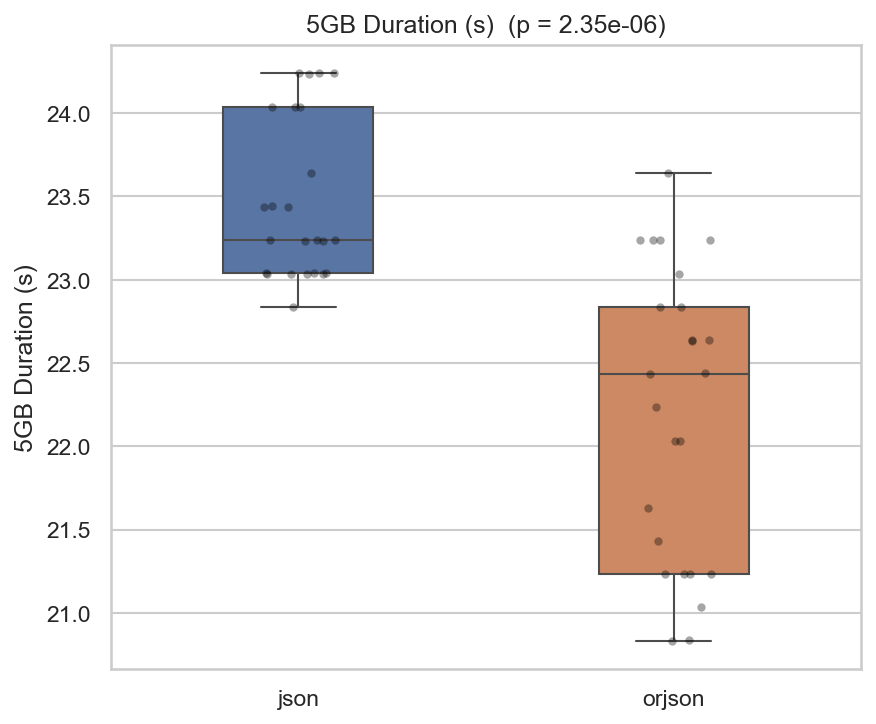
The duration comparison reveals a statistically significant difference between the two libraries. orjson completes the deserialization workload faster than the standard json library (mean ~22.2 s vs ~23.5 s for the 5 GB dataset; p < 0.001, Cliff’s d = 0.79). This confirms the performance claims made by the orjson documentation and establishes the foundation for examining whether this speed advantage translates into energy savings through the “Race to Sleep” principle.
CPU Energy Consumption
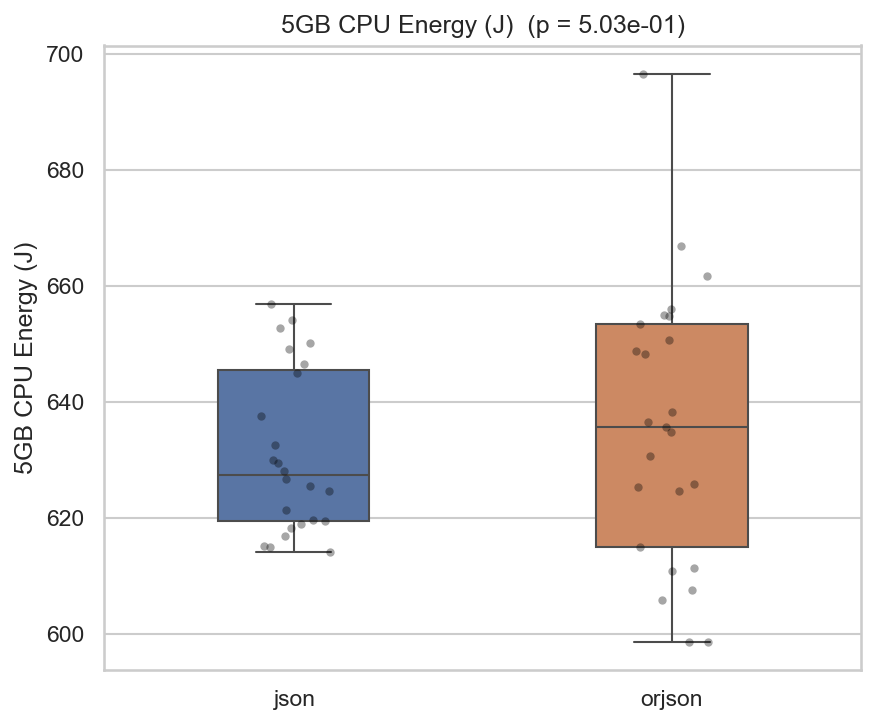
The total CPU energy consumption (measured via the RAPL CPU_ENERGY counter) shows that json and orjson consume comparable total CPU energy (~631 J vs ~636 J on average). Crucially, this difference is not statistically significant (Mann-Whitney U, p = 0.50), meaning we cannot conclude either library is more energy-efficient at the package level for this workload size. Notably, orjson exhibits considerably higher variance in energy consumption (~24 J std vs ~14 J std for json), making json the more predictable choice for the 5 GB workload.
Single-Core (CORE0) Energy Consumption
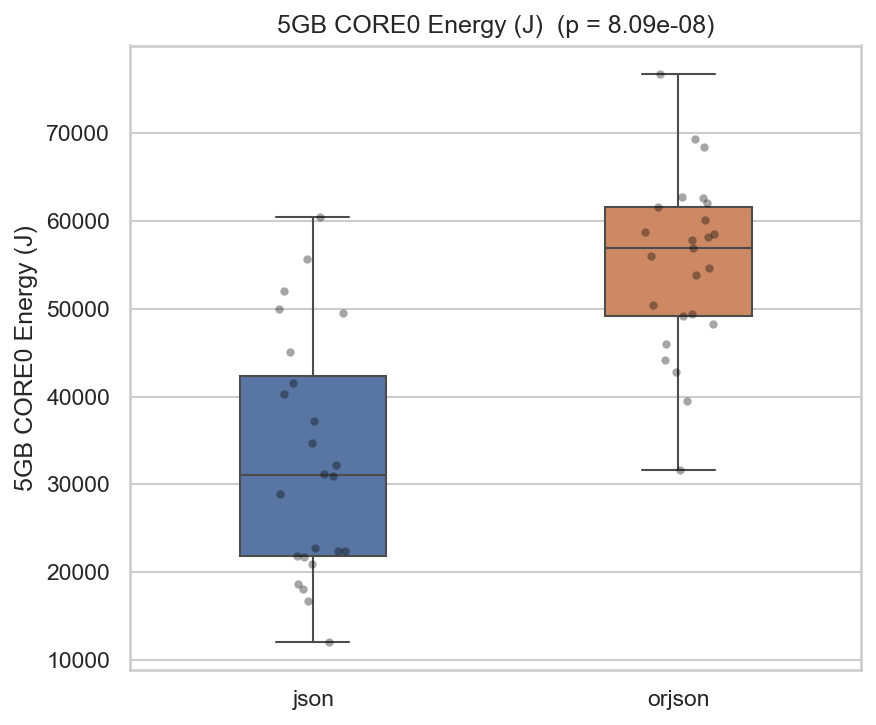
The CORE0 energy metric isolates energy consumption on a single CPU core, providing insight into the single-threaded behaviour of both libraries. Interestingly, orjson shows substantially higher CORE0 energy consumption (~55 kJ) compared to json (~33 kJ) for the 5 GB workload (p < 0.001, Cohen’s d = -1.86). This large effect suggests that orjson places a considerably heavier sustained load on the primary core. The higher total-package energy in json is thus spread across more micro-architectural state transitions, while orjson concentrates its work on CORE0. From a single-core energy perspective, json is more frugal, a result that partially contradicts the “Race to Sleep” hypothesis at the core level.
Average CPU Power Draw
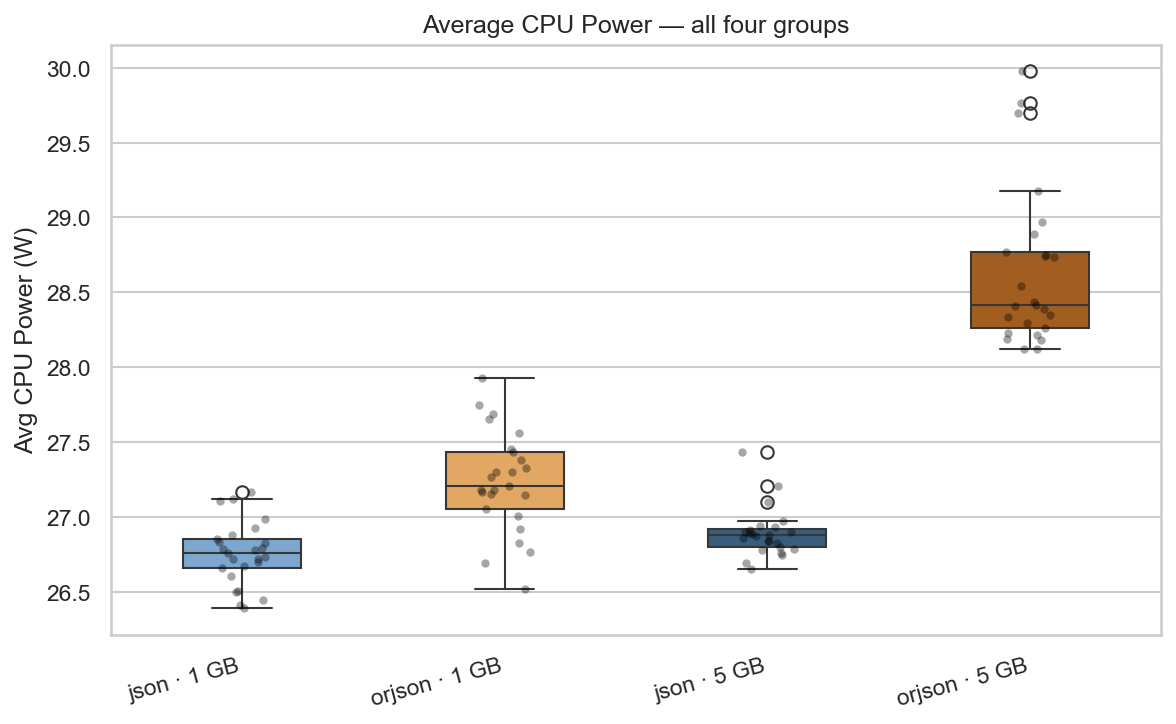
The average CPU power draw, plotted across all four experimental groups (json and orjson, 1 GB and 5 GB), reveals a consistent pattern: json exhibits lower average power consumption than orjson at both dataset sizes (~26.9 W vs ~28.6 W for 5 GB; ~26.8 W vs ~27.2 W for 1 GB). This aligns with the “Race to Sleep” model: orjson’s Rust-based implementation and SIMD optimizations drive the CPU harder, resulting in higher instantaneous power regardless of dataset size. The magnitude of the power gap narrows at 1 GB (~0.5 W) compared to 5 GB (~1.7 W), suggesting that the overhead of orjson’s acceleration is relatively more pronounced for longer, sustained workloads.
Energy vs Duration Trade-off
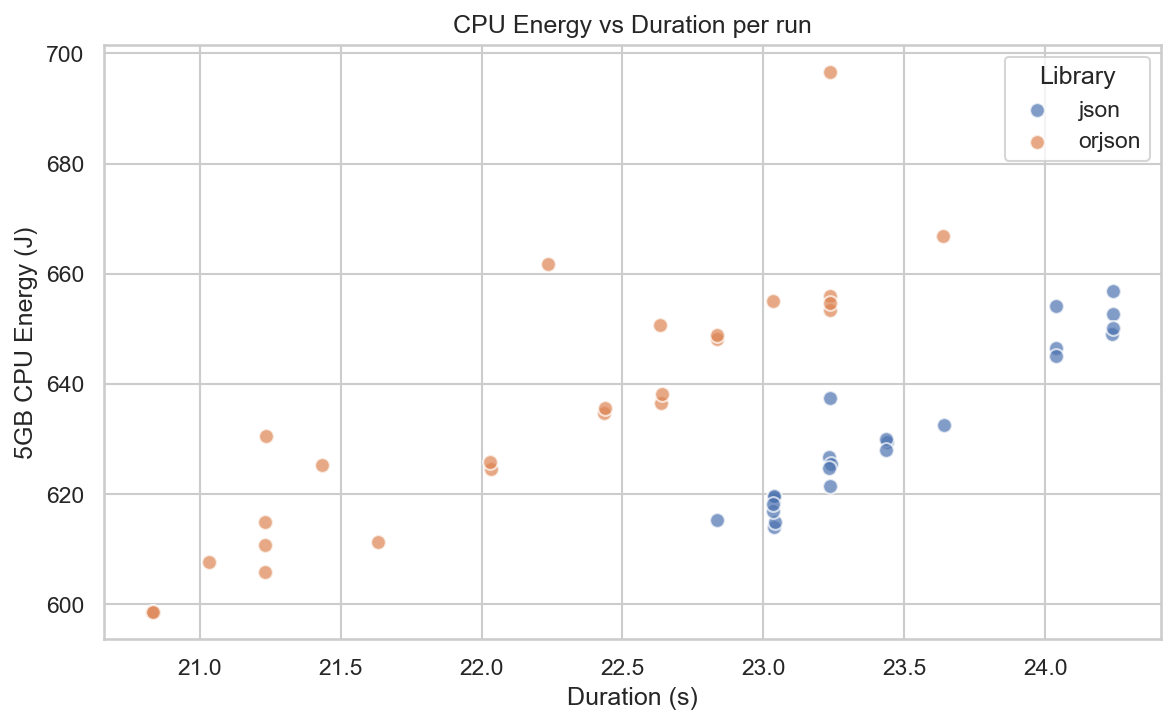
Figure above shows a clear positive correlation between execution time and CPU energy: longer runs consume more energy for both libraries.
Although orjson consistently completes the workload faster (~5.4% improvement for the 5 GB dataset), the total CPU energy picture is more nuanced. For the 5 GB workload, its data points are shifted toward lower durations but higher energy values, with greater variance compared to json. The ~5.4% runtime reduction is insufficient to compensate for the elevated power draw, resulting in statistically indistinguishable CPU energy consumption (p = 0.50).
In this setup, orjson optimizes for speed while json remains marginally more predictable in energy consumption for large, sustained workloads.
Cross-Dataset Energy Comparison (1 GB vs 5 GB)
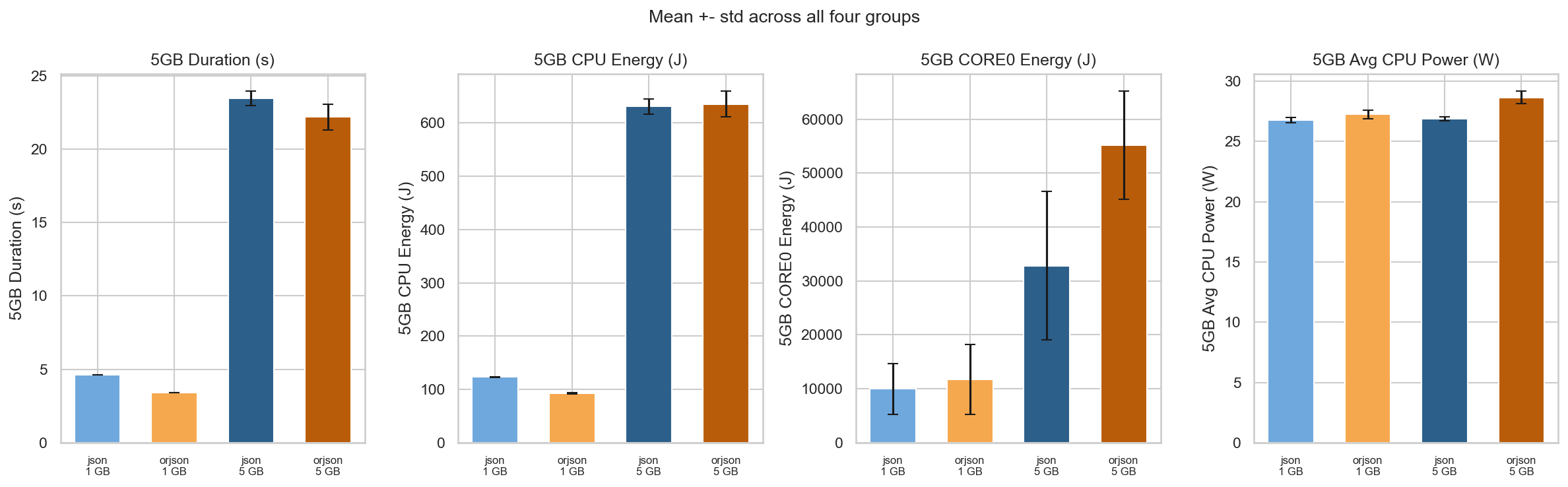
Scaling the analysis to include the 1 GB dataset reveals an important nuance. For the smaller workload, orjson is clearly more energy-efficient: it consumes ~92.7 J of CPU energy vs ~123.3 J for json, a ~25% reduction that is highly significant (p ~ 0, Cohen’s d = 28.6). The ~26% speedup at 1 GB (3.4 s vs 4.6 s) is large enough that the “Race to Sleep” principle holds: the CPU spends substantially less time at high-power levels before finishing the job.
In contrast, at 5 GB the ~5.4% speedup does not overcome the overhead of orjson’s higher power draw, leaving total CPU energy statistically unchanged. This suggests a threshold effect: below a certain workload size, orjson’s acceleration outpaces its power overhead; above it, the two libraries converge in energy cost at the package level.
The average power gap between json and orjson is consistent across both sizes (json always draws less power), confirming that the fundamental power trade-off is a stable property of these libraries rather than an artefact of any particular run length.
Time-Series Analysis: Cumulative Energy Delta
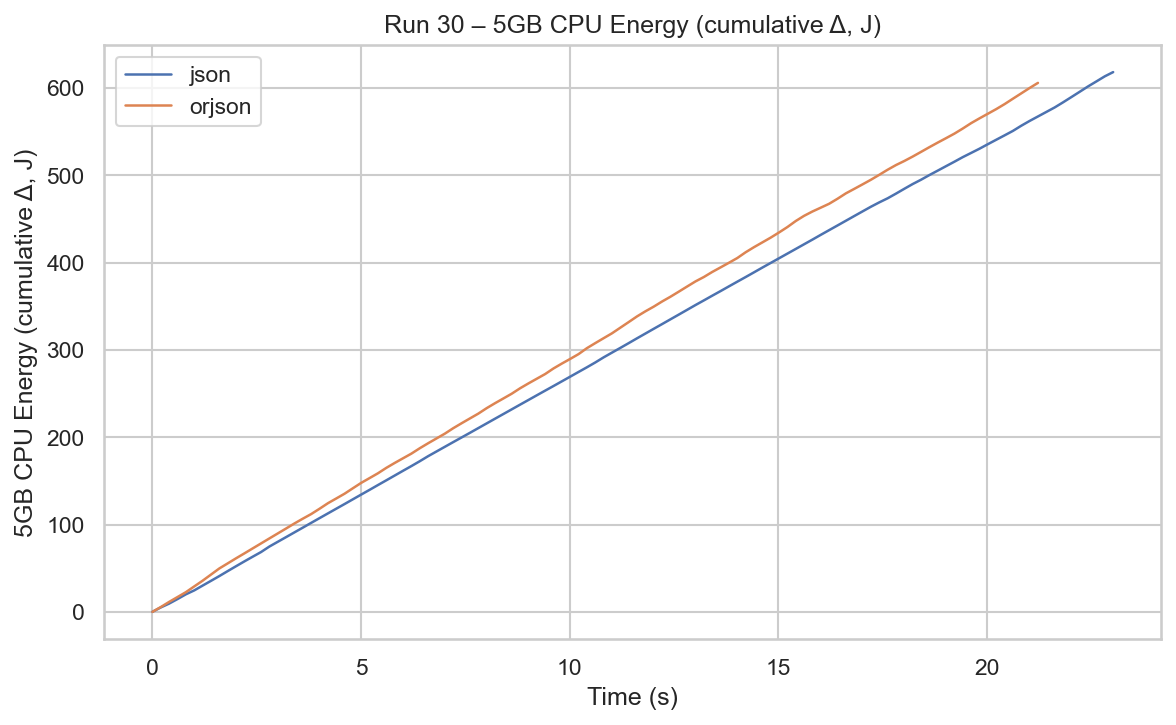
The cumulative CPU energy curves increase almost linearly for both libraries, indicating stable power usage throughout execution.
orjson shows a steeper slope, meaning higher instantaneous power consumption. Although it finishes earlier, its curve remains slightly above json, resulting in higher total CPU energy by the end of the run.
This confirms that the faster execution of orjson does not compensate for its increased power draw in this workload.
Conclusion
This study investigated whether the performance advantages of orjson translate into measurable energy savings compared to the standard Python json library.
RQ1. Our results show that orjson executes the 5 GB workload ~5.4% faster, but this does not translate into statistically significant CPU energy savings at that scale (p = 0.50). For the same library at the 1 GB scale, however, orjson achieves a ~26% speedup and reduces total CPU energy by ~25% (~93 J vs ~123 J, p ~ 0). Thus, whether orjson provides energy savings depends critically on workload size.
RQ2. The relationship between library choice and energy consumption is not consistent across dataset sizes. At 1 GB, orjson is clearly more energy-efficient, confirming the “Race to Sleep” principle — the speedup is large enough to outweigh the higher instantaneous power draw. At 5 GB, the speedup narrows to ~5.4% and is insufficient to compensate, leaving total CPU energy statistically indistinguishable between the two libraries. Average CPU power, however, remains consistently higher for orjson regardless of dataset size.
Regarding the Race to Sleep hypothesis, our findings show that it holds at the 1 GB scale but breaks down at 5 GB, suggesting a threshold effect. The magnitude of the performance advantage matters: a ~26% speedup is sufficient to realize energy savings, whereas a ~5% speedup is not.
In conclusion, orjson is the superior choice for both performance and energy efficiency when processing datasets in the 1 GB range. At larger scales (5 GB), the energy advantage disappears, though json maintains a slight edge in stability. Developers processing large files repeatedly on power-constrained systems should benchmark their specific workload size before choosing between the two libraries.
References
-
Crockford, D. (2006). The application/json Media Type for JavaScript Object Notation (JSON). RFC 4627. IETF. Retrieved from https://tools.ietf.org/html/rfc4627 ↩ ↩2
-
Van Rossum, G., & Warsaw, B. (2001). PEP 8 - Style Guide for Python Code. Python Software Foundation. Retrieved from https://www.python.org/dev/peps/pep-0008/ ↩
-
ijl. (2024). orjson: Fast, correct Python JSON library. GitHub Repository. Retrieved from https://github.com/ijl/orjson ↩ ↩2 ↩3
-
Pathak, A., Hu, Y. C., & Zhang, M. (2012). Where is the energy spent inside my app?: fine grained energy accounting on smartphones with Eprof. Proceedings of the 7th ACM European Conference on Computer Systems, 29-42. ↩ ↩2
-
Belkhir, L., & Elmeligi, A. (2018). Assessing ICT global emissions footprint: Trends to 2040 & recommendations. Journal of Cleaner Production, 177, 448-463. https://doi.org/10.1016/j.jclepro.2017.12.239 ↩
-
Intel Corporation. (2023). Intel 64 and IA-32 Architectures Software Developer’s Manual. Volume 3B: System Programming Guide, Part 2. ↩
-
Sallou, J., Cruz, L., & Durieux, T. (2023). EnergiBridge: Empowering software sustainability through cross-platform energy measurement. arXiv preprint. https://doi.org/10.48550/arXiv.2312.13897 ↩